Coursework · Deep Learning
Editorial Assistant
Three MLP frameworks (scikit-learn, TensorFlow, PyTorch) on the same multi-task problem: predict an article's popularity, sentiment polarity, and subjectivity from structural metadata only. Deep multi-task learning wins where the task is hard, loses where it isn't, and the simple sklearn MLP beats the deep ones at predicting tone.
Context
The Deep Learning module at ESAIP (S7, autumn 2025) sets a short team project on a free-choice dataset. Constraints: solve the same problem across three frameworks (scikit-learn, TensorFlow, PyTorch), and include both classification and multi-output regression on structured data. Code on Moodle, ten-minute oral defense, peer-graded contributions.
We picked UCI's Online News Popularity (39,644 Mashable articles, 58 features) and framed it as an editorial assistant: given an article's structural metadata — word count, image count, publication day, thematic channel, LDA topic mix — predict its popularity, its sentiment polarity, and its subjectivity. Team of three; we split the implementation across the three required frameworks with shared preprocessing and a common evaluation pipeline so the comparison stayed fair.
The framing
A standard editorial pipeline uses sentiment as an input feature to predict popularity: how positive an article is, how subjective, what its topic is. Our framing inverts the dependency. Use only the structural choices the editor actually controls — word count, number of images and videos, publication day, channel, topic distribution — and predict both popularity and sentiment as outputs. The bet is that structure alone carries enough signal to forecast tone. If it does, an editor can simulate before writing: "a 700-word article with two images, published Monday on the technology channel — what tone will it land?"
The approach
Three implementations of the same MLP family. Scikit-learn
runs separate, shallow models per task. TensorFlow and PyTorch
share a multi-task architecture: a stack of dense layers feeds
task-specific heads — a classification head for
is_popular, regression heads for
log_shares, sentiment polarity, and subjectivity.
Same preprocessing across all three: stratified split, robust
scaling, log-transform on the bimodal share distribution.
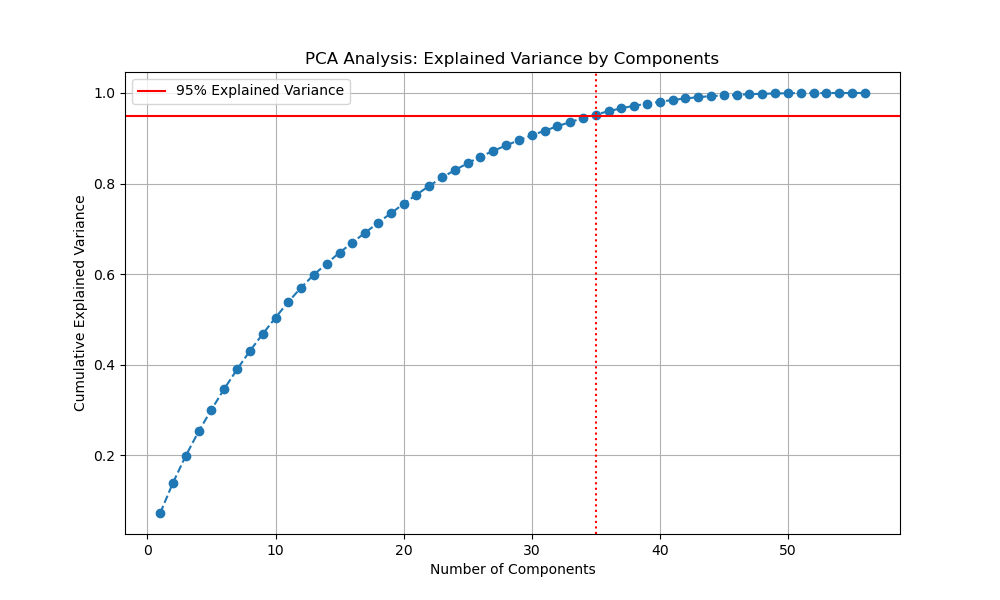
PCA exploration on the 58 features showed substantial inter-feature redundancy — 95% of variance captured by 35 components — which justified the regularisation choices but was not applied as a hard dimensionality cut in the final pipeline.
Result
Three frameworks, four metrics, twelve numbers. The contrasts:
Popularity (regression on log_shares). The hard task. Both deep frameworks land at R² ≈ 0.146 (TensorFlow 0.146, PyTorch 0.146); scikit-learn 0.103. The deep multi-task models capture about 40% more variance than the shallow baseline.
Sentiment polarity (regression). The simple model wins decisively: scikit-learn R² = 0.838; PyTorch 0.656; TensorFlow 0.498. Subjectivity follows the same pattern (sklearn 0.585, both deep models around 0.48). The hypothesis: the multi-task loss in TF and PyTorch sacrifices accuracy on the easy task to chase the hard one.
Classification (is_popular). All three within a few thousandths of each other on AUC: PyTorch 0.716, TensorFlow 0.715, scikit-learn 0.710. The deep frameworks have a marginal edge — well within noise.
The professor's challenge
During the design review, the supervisor pushed back on the framing:
Most of those regression targets would normally be used as input context features. I'm not sure how this will turn out.
The objection is fair. Sentiment polarity and subjectivity are usually inputs to a popularity model, not outputs. We were running the dependency in the unconventional direction. The defence: that's the whole point of an editorial assistant. The editor controls structure, not tone — tone emerges from structure once the article is written. If structure → tone is learnable, a writer can simulate the tone of an article they haven't yet written by varying the levers they actually control.
The R² = 0.838 on sentiment polarity says the inversion is learnable. Structure carries about 84% of the variance of tone on this dataset. The unconventional framing produced the most interpretable signal of the entire experiment.
Recommendation
For a real deployment, a hybrid stack is the honest answer: PyTorch for popularity prediction and binary classification (where deep multi-task learning genuinely helps) and scikit-learn for sentiment and subjectivity (where the shallow model wins on both performance and inference cost). The assumption that deeper is always better is wrong on structured data with unequal task difficulty.