Coursework · Natural Language Processing
Sentiment Analysis
Three-class sentiment classifier on 37,427 Google Play Store reviews. DistilBERT fine-tuned with class-weighted loss for the 4.65× imbalance — 95.2% test accuracy, 93.9% macro F1. A soft-voting ensemble across three seeds tested for robustness; the gain was marginal.
Context
The NLP module at ESAIP gives a solo final project. The brief: train a sentiment-analysis model on the Kaggle Google Play Store Reviews dataset (or scraped equivalent), document every function, submit a Jupyter notebook plus an 8-slide oral defense. The top three most accurate models in the cohort get shared with the class — accuracy is the only ranking criterion.
Solo project. The strategic call up front: pre-trained Transformers consistently outperform classical architectures on sentiment by 10-15 accuracy points, so the priority was the fine-tuning Transformer. The other models — Logistic Regression, MLP, BiLSTM with attention, TextCNN — were trained alongside as pedagogical baselines, to see the gap rather than just claim it.
The problem
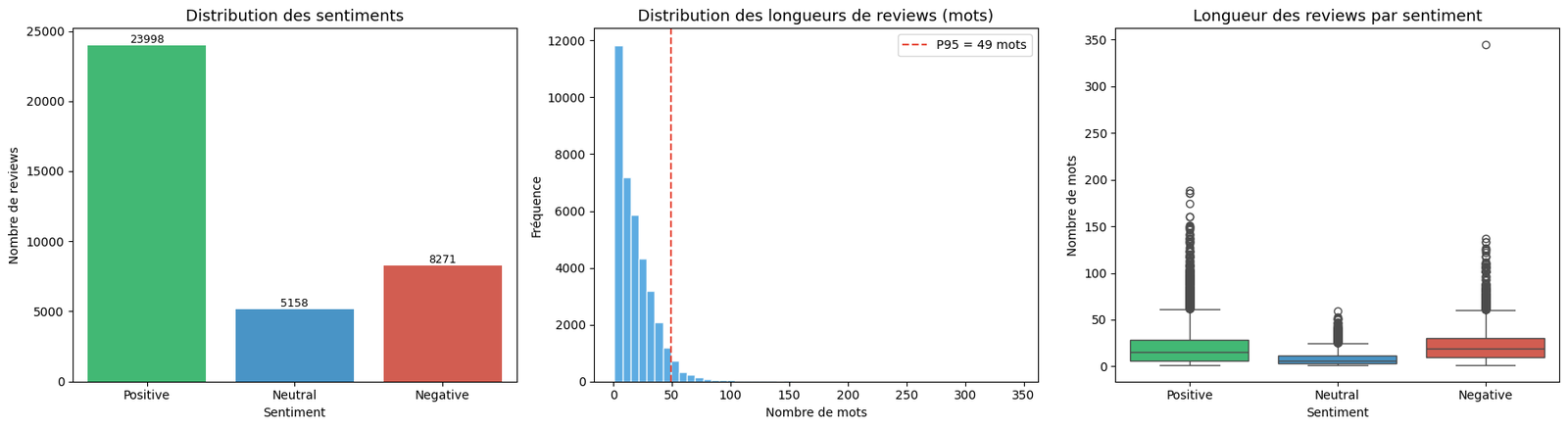
37,427 English reviews, mapped from star rating to three classes: 1-2★ negative, 3★ neutral, 4-5★ positive. The distribution is uneven — 23,998 positive, 8,271 negative, 5,158 neutral, a 4.65× ratio between the largest and smallest class. Median review length is 14 words, with the 95th percentile at 49 words. Short, noisy, real user-written text where the neutral middle is the hardest class to pin down.
The approach
DistilBERT was the deliberate choice over BERT: 67M parameters versus 110M (60% of the size), six Transformer layers versus twelve, 2× faster inference, with about 97% of BERT's downstream performance per the distillation paper. For a one-week project where iteration speed matters, the trade was straightforward.
Two preprocessing pipelines run in parallel because the
classical models and the Transformer have incompatible
conventions. The classical pipeline does the textbook NLTK
treatment — lowercase, punctuation removal, stop-word
filtering, manual vocabulary with <PAD> and
<UNK> tokens. The Transformer pipeline does
almost nothing: the HuggingFace tokenizer (WordPiece, 30,522
tokens) handles everything, and stop-words are kept because
self-attention needs them. Mixing the two pipelines would
have silently corrupted the comparison.
Class imbalance is handled via weighted cross-entropy
(w_k = N / (K × N_k)), penalising errors on rare
classes more than on common ones, rather than oversampling.
Stratified split: 72% train, 13% validation, 15% test. Best
epoch picked by lowest validation loss; on the final run, that
was epoch 2 with val_loss = 0.2328.
Result
On the held-out test set of 5,615 reviews: 95.2% accuracy, 94.1% macro precision, 93.7% macro recall, 93.9% macro F1. The Transformer dominated the classical baselines by the expected margin — Logistic Regression and MLP both stalled around 86-88% accuracy on this dataset, BiLSTM with attention and TextCNN hovered around 90-91%, the Transformer cleared 95%.
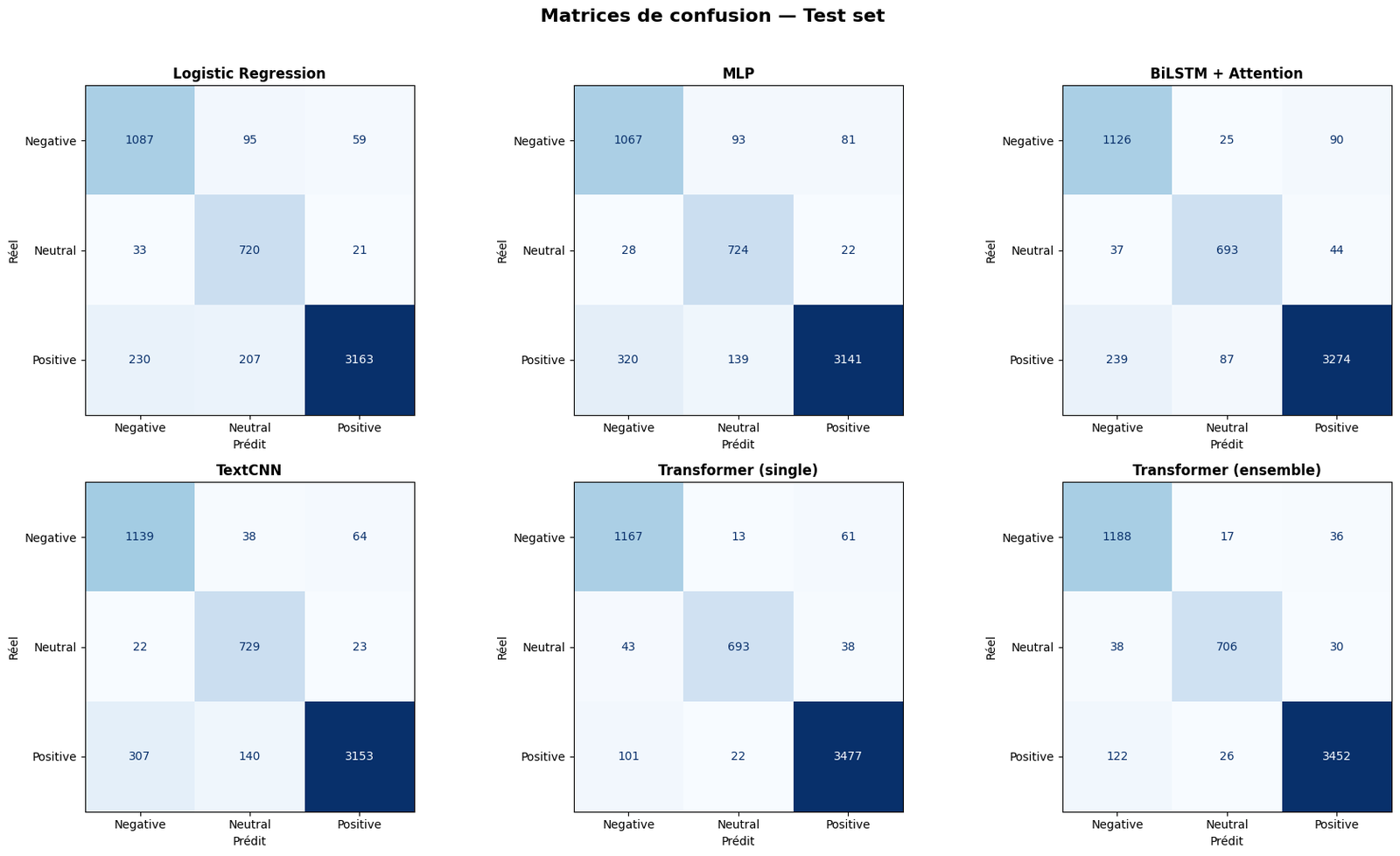
A soft-voting ensemble across three seeds (42, 123, 456) was tested for robustness: average the softmax probabilities, predict the argmax. The gain over the single Transformer was marginal — the ensemble shifts a handful of borderline decisions but doesn't change the overall accuracy. On this dataset the single fine-tuned model is already strong enough that ensembling buys very little. Worth noting as evidence rather than as a silver bullet.
Around the model
The notebook is structured as documented milestones (M0
fondations, M1 pipeline données, M2 transformer, M3 baseline +
MLP, M4 deep learning, M5 évaluation, M6 finalisation), each
tied to specs written before any code. Every function carries
a docstring stating purpose, inputs and outputs, per the
submission rules. Two prediction functions are exposed at the
end — predict_transformer() for single-model
inference and predict_transformer_ensemble() for
the soft-voting variant — so that the model is callable on
unseen comments without re-running the notebook.